





Benefici e rischi dell'uso dell'intelligenza artificiale nelle previsioni meteo

Tra i molti ambiti in cui si guarda con interesse alle potenzialità dell'intelligenza artificiale, che sta vivendo una fase di accelerazione grazie all'aumento esponenziale della capacità di calcolo e alla grande disponibilità di dati, c'è quello delle previsioni meteo.
Due studi recentemente pubblicati sulla rivista Nature hanno mostrato risultati impressionanti raggiunti attraverso l'applicazione di due modelli meteorologici di intelligenza artificiale, opportunamente addestrati (in un caso attraverso 40 anni di dati osservati e milioni di parametri e nell'altro attraverso una combinazione di osservazioni ed equazioni numeriche) e hanno così acceso l'attenzione sui benefici, ma anche sui possibili rischi, collegati a questi nuovi sviluppi.
Il primo modello si chiama Pangu Weather ed è stato messo a punto da ricercatori che lavorano per la società cinese Huawei, colosso dell'elettronica e della telefonia. Si concentra sulle previsioni a medio raggio (fino a sette giorni nel futuro) e si è dimostrato circa 10.000 volte più veloce rispetto al sistema attualmente utilizzato dal Centro europeo per le previsioni meteorologiche a medio raggio (ECMWF), alla stessa risoluzione spaziale e con precisione comparabile. Va però subito precisato che Pangu Weather prevede variabili come la temperatura, la velocità e la pressione del vento ma non estende il suo raggio di azione alle precipitazioni. Il secondo modello è denominato NowcastNet e si concentra invece esclusivamente sul breve termine con l'obiettivo di prevedere gli eventi piovosi, da leggeri a moderati, e le precipitazioni estreme in una scala temporale di qualche ora.
In un articolo pubblicato su Nature come commento alle due ricerche vengono messi in evidenza i vantaggi dei modelli di previsione meteorologica basati sull’intelligenza artificiale ma anche i rischi e gli attuali limiti di natura tecnica, tra cui la possibilità che gli eventi estremi, a seconda della durata dei registri di dati utilizzati per addestrare il modello AI, siano sottocampionati. Gli autori, Imme Ebert-Uphoff e Kyle Hilburn (Cooperative Institute for Research in the Atmosphere, Colorado State University), affermano che "in linea di principio, gli aumenti della velocità computazionale potrebbero produrre immensi benefici" tra cui la possibilità di "integrare processi fisici (come la propagazione degli incendi) che hanno effetti pronunciati sulla qualità dell’aria e sulla salute umana, ma richiedono molto tempo per essere eseguiti su computer standard". Tuttavia, puntualizzano gli esperti, "l'intelligenza artificiale presenta anche potenziali rischi sia per il nowcasting che per le previsioni meteorologiche globali" e per questo motivo è fondamentale che i meteorologi acquisiscano una formazione specializzata, siano coinvolti nella progettazione di questi nuovi sistemi previsionali e imparino a interpretarli correttamente.
Per comprendere meglio come vengono effettuate oggi le previsioni meteo che si basano su modelli “convenzionali" e quale contributo possono offrire l’intelligenza artificiale e i sistemi di machine learning nel campo delle scienze dell’atmosfera abbiamo intervistato Francesco Domenichini, meteorologo di Arpa Veneto.
Il futuro delle previsioni meteo sta guardando con grande attenzione alle opportunità dell’intelligenza artificiale e due recenti studi scientifici pubblicati sulla rivista Nature hanno evidenziato grandi potenziali per i sistemi che si basano su questo approccio. Prima di entrare più nel dettaglio di vantaggi, limiti ed eventualmente anche rischi dell’IA applicata alla meteorologia, possiamo spiegare come vengono effettuate oggi le previsioni meteo che si basano su modelli “convenzionali”?
La previsione meteorologica, da diversi anni, si basa in prevalenza sull’impiego degli output della modellistica numerica, mediante l’utilizzo diretto del dato, o una post processazione, o l'analisi ed interpretazione fatta da personale con preparazione tecnico-scientifica. A questo si aggiungono gli strumenti osservativi, che hanno un ruolo prevalente nella previsione a brevissimo termine o nella analisi in tempo reale e a posteriori.
La modellistica numerica per la meteorologia consiste in sistemi di calcolo in cui possiamo distinguere tre elementi principali. La prima è la fase diagnostica, in cui viene costruita la cosiddetta “analisi” dello stato iniziale della previsione, partendo da dati raccolti da vari sistemi osservativi (principalmente dati di vento, pressione, temperatura, umidità), tra cui stazioni al suolo, radiosondaggi, boe meteorologiche, stazioni su veicoli mobili, dati satellitari. Tutti questi dati sono riportati su una griglia regolare che descrive la condizione iniziale dell’atmosfera. C'è poi la fase di calcolo differenziale, in cui viene simulata l’evoluzione dell’atmosfera dallo stato iniziale, mediante calcolo alle differenze finite basato sulle leggi descrittive dell’atmosfera, tra cui le leggi di Navier Stokes, conservazione della massa, equazione di stato dei gas, equazione idrostatica: questo produce l’evoluzione nel tempo delle variabili descrittive dell’atmosfera (primariamente pressione, temperatura, velocità e direzione del vento, contenuto di vapore d’acqua). La fase di calcolo, con metodi fisici o parametrici, è invece quella che consente di ottenere le previsioni numeriche di quantità che non sono esplicitamente descritte dal calcolo al passaggio precedente (precipitazione e sue componenti, nuvolosità, visibilità).
Esistono due categorie principali di modellistica meteorologica: la modellistica globale e quella locale. Un modello globale lavora sull’intera atmosfera terrestre, elabora quindi dati iniziali provenienti da tutto il mondo, e in generale impiega molte più risorse sia di calcolo sia in termini di quantità di dati iniziali impiegati. Il modello locale utilizza come condizione al contorno l’output di un modello globale, producendo una previsione su scala geografica minore, aggiungendo informazione morfologica del territorio, maggiore dettaglio geografico, e in molti casi aggiungendo dati meteorologici di scala locale.
L’ordine di grandezza del passo di griglia orizzontale del dato è di 10 km per i modelli globali, e di 1 km per i modelli locali, mentre il passo di griglia verticale è variabile con la quota, dalle decine di metri vicino al suolo, al km in alta atmosfera, nei modelli globali, e minore nei modelli locali anche in funzione delle esigenze per cui viene impiegato dal modello stesso.
Un capitolo a parte lo occupa la modellistica di tipo Ensemble, che per brevità potremmo vedere come un sistema modellistico multiplo, e che genera informazione di tipo probabilistico anzichè univoco (deterministico). Si osservi che la modellistica numerica in meteorologia è una materia in continua evoluzione, e quanto detto sopra è soltanto un modesto accenno, con valore limitato alla situazione degli ultimi 5-10 anni.
I risultati della previsione numerica in meteorologia possono andare incontro a tre utilizzi: l'impiego diretto del dato numerico come informazione pressoché “nuda", pratica abbastanza comune in molti sistemi previsionali automatici; la post-processazione del dato che consiste nel derivare dal dato numerico altre informazioni, come aggregati spaziali o temporali, o informazioni rielaborate con funzioni, maschere o filtri correttivi, per ottenere grandezze non disponibili direttamente dalla modellistica o valori più coerenti con le osservazioni e l'analisi esperta dei dati dei modelli: questi vengono visualizzati in modo mirato ad agevolare l'analisi da parte di uno specialista. Questo è il caso soprattutto del previsore mirato alle attività di comunicazione e di allertamento (attività di Protezione Civile).
Per questo ultimo tipo di analisi esistono molte forme di visualizzazione grafica, mappe, grafici temporali, viste tabellari, con opportune associazioni di variabili, che offrono al previsore una panoramica sintetica di un grande numero di dati numerici. L’esperienza previsionale permette poi di collegare quanto disponibile dal modello numerico ad una serie di modelli concettuali e di comportamenti tipici delle strutture meteorologiche, giungendo ad elaborazioni di sintesi con finalità decisionale (allertamento e valutazioni operative di qualsivoglia genere).
E' importante citare sinteticamente anche il contributo alla previsione dato dalle osservazioni in tempo reale, in particolare Radar (per le precipitazioni) e Satellite meteorologico (superficie terrestre, nuvolosità e altre componenti gassose in atmosfera), nonchè le reti di stazioni di telemisura. Queste osservazioni vengono impiegate direttamente dal previsore, ma possono entrare anche a far parte del complesso sistema di inizializzazione dei modelli meteorologici. Inoltre a caduta dai dati osservativi diretti possono seguire metodi automatici per l'allertamento e la previsione a brevissimo termine.
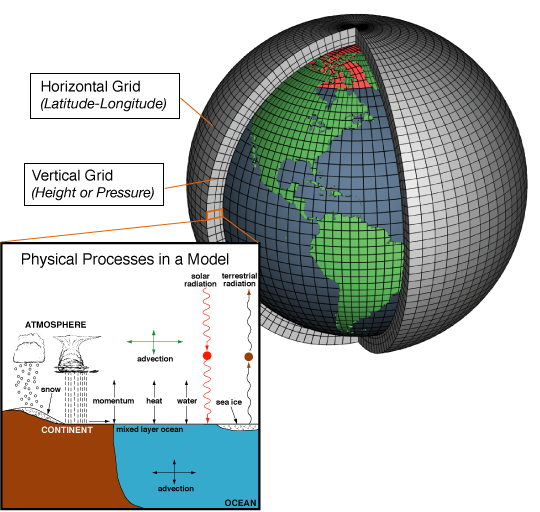
Schema di griglia tridimensionale e di processi di fisici all'interno di un modello numerico per la meteorologia. Fonte Noaa / Wikipedia
Fino a dove riesce ad arrivare, in termini di dettaglio spaziale e capacità di anticipo temporale, una previsione meteo effettuata con modelli fisico-matematici?
La risposta può sembrare compresa nella descrizione della risoluzione e dell'estensione temporale dei modelli ma la realtà è ovviamente diversa e legata alla effettiva efficacia previsionale dei suddetti modelli, che è sicuramente inferiore alla risoluzione nominale dei dati numerici di previsione.
Esiste una disciplina che si occupa di dare la corretta risposta a questa fondamentale questione. Prende il nome di “verifica dei modelli previsionali” e consiste nel mettere a confronto gli esiti previsti con la realtà riscontrata, producendo così svariati indici di valutazione dell'esito della previsione numerica, che mettono in evidenza diversi aspetti della previsione e soprattutto del suo errore.
Gli approcci che caratterizzano questa disciplina sono diversi e includono la verifica eyeball, ovvero la verifica a colpo d’occhio da parte dell’utilizzatore; la verifica di predittori continui, ovvero errore medio, varianza, bias e altri, calcolati su valori continui, come si utilizzano nella fisica sperimentale classica; la verifica dicotomica, che considera le tabelle di contingenza si/no di coppie predittore/evento; la verifica multicategoriale, analoga alla precedente ma estesa a più categorie rispetto ai valori binari si/no; la verifica per predittori di tipo probabilistico.
Tutti i metodi mettono comunque in rilievo aspetti analoghi e tra i principali ci sono sicuramente l’errore, il bias (quindi la distinzione tra sottostime e sovrastime) e la reliability (per previsioni probabilistiche).
Si può facilmente immaginare che non esista una sola risposta alla domanda sulla validità temporale di queste informazioni, non solo per la diversità di approccio alla verifica, ma anche per le diverse scale di aggregazione spaziali e temporali del predittore e dell’osservato, nonchè per la diversa predicibilità dei parametri stessi (pressione, temperatura, vento, precipitazione...).
Un altro motivo per cui la risposta è estremamente variabile è la diversa riproducibilità delle diverse situazioni meteorologiche. Per esempio in condizioni anticicloniche stabili si tende ad avere una maggiore predicibilità media di alcune variabili rispetto a condizioni di marcata variabilità.
Per avere un'idea generale della qualità della previsione numerica nei giorni i principali centri di ricerca meteorologica mettono a disposizione delle tavole di sintesi contenenti "scores" ed errori delle previsioni prodotte.
In generale, guardando queste tavole di verifica, si osserva come le performance dei modelli meteotologici globali evolvono e complessivamente migliorano negli anni, e si osserva anche quanto la previsione nell'avanzare della distanza temporale dal momento di avvio della simulazione presenti un discreto calo di performance, comunque attenuato man mano che nei decenni migliora la tecnologia computazionale e vengono operate scelte migliorative nella modellistica.
Nell'ottica dell'utente, si sente spesso dire che le previsioni non sono attendibili oltre i 3-5-7 giorni: tutti questi valori sono potenzialmente veri, in dipendenza dei fattori descritti, e dal valore che diamo al termine "attendibile". Un approccio mirato alle esigenze del'utenza suggerisce che la previsione abbia performance accettabili solo fino ai 5-7 giorni, quindi spingersi oltre ha poco senso per l'impiego privato in termini di programmazione delle attività.
Nell'ottica del previsore meteorologico, specie se mirato alle attività di allertamento, il range desiderabile è tra le 24 e le 48-72 ore; l'attivazione di procedure di allerta idrometeorologica per situazioni più distanti nel futuro è considerato, in modo abbastanza unanime, troppo esposto alla possibilità di falsi e mancati allarmi. Non a caso, di norma, le procedure di allertamento sono emanate per intervalli compresi tra le 12 e le 48 ore, sia a livello italiano che anche nei servizi meteo di altre nazioni.
Che ruolo possono giocare l’intelligenza artificiale e i sistemi di machine learning nel campo delle tecnologie previsionali?
L'utilizzo di strumenti informatici della sfera dell'IA ha raggiunto anche la meteorologia da diversi anni. Tali strumenti sono perlopiù complementari alle informazioni di tipo osservativo e computazionale di cui abbiamo parlato fino ad ora.
I modelli meteorologici menzionati sono sistemi di calcolo basati sulla fisica dell'atmosfera e dell'oceano e sull'interazione fra i due, e come abbiamo visto portano con se errori previsionali variabili, sempre in qualche modo presenti.
A questo punto due cose vanno evidenziate: l'errore nelle simulazioni modellistiche è al momento ineludibile, va sempre considerata e porta con sè dell'informazione aggiuntiva. Parallelamente i risultati delle diverse simulazioni modellistiche sono sempre più o meno diverse, sia fra diverse catene di calcolo sia tra corse diverse dello stesso modello.
Considerate queste osservazioni, è evidente il ruolo giocato dall'operatore umano, e quindi dall'intelligenza: valutare tutte le informazioni anche se diverse e potenzialmente incoerenti, tenere in considerazione variabilità ed errore di queste informazioni, trarne conclusioni di sintesi e operare scelte conseguenti. A questo si aggiunge l'esigenza della rivalutazione in tempo reale della bontà delle scelte intraprese e chiaramente l'esigenza di una verifica a posteriori.
Nel suo complesso infatti l'attività previsionale si combina continuamente con la componente osservativa, data dalle misure al suolo, radar, satellite e altro. Questa combinazione permette di rivalutare passo passo la qualità della previsione prodotta in precedenza e riformularla adeguatamente alle nuove osservazioni, il tutto in attesa di ulteriori informazioni derivate dalla modellistica meteorologica.
Si vede quindi che nell'attività della previsione si fondono elementi di pensiero creativo, capacità comunicativa, esperienza tecnica, conoscenza dei fenomeni e qualità nella sintesi. Tutte queste capacità possono concettualmente venire riportate a schemi logici, ma data la loro complessità non sono facili da simulare, a causa della varietà degli esiti, che possono eventualmente uscire dagli schemi già osservati.
Costruire la previsione meteorologica a discendere dalle osservazioni in tempo reale e dalle previsioni prodotte dai modelli meteorologici è una applicazione complessa e risulta un ideale oggetto di indagine per chi lavora con l'Intelligenza Artificiale.
Si può sicuramente lavorare ad applicazioni esperte che soddisfino parte di questi requisiti, eventualmente anche con aspetti migliorativi rispetto a quella dell'intelligenza umana.
Ecco che si apre uno spettro di possibili applicazioni. Alcuni esempi sono il supporto dell'analisi, come potrebbe essere un sistema che si esercita nel riconoscimento delle strutture meteorologiche previste su grande scala (clustering) e le associa all'esperienza di accadimenti pericolosi; il perfezionamento dell'osservazione con mappature intelligenti (anche con alberi decisionali) per completare l'informazione sul territorio, dove non sono possibili osservazioni dirette; la scelta dello scenario previsto grazie ad una processazione che giorno per giorno seleziona tra lo spettro di offerta dai vari centri di calcolo il modello meteorologico più efficace; e l'ambito della comunicazione, per esempio un sistema che alla richiesta dell'utente risponda con un approccio di selezione ed aggregazione dell'informazione modellistica, mirata alla soddisfazione della richiesta più che alla perfezione e rivalutazione della previsione.
Mi sento di affermare che la simulazione di tutte queste attività in una sola intelligenza artificiale risulta ancora piuttosto inaccessibile, mentre le singole componenti possono dare risultati di valore.
Come viene addestrato un modello di machine learning e quali variabili vengono considerate?
Dipende da cosa vogliamo realizzare. Premetto che l'IA e relative applicazioni non sono il mio ambito di lavoro, ma per dare un'indicazione di massima, nel machine learning si applicano 3 metodi, detti anche paradigmi, di apprendimento, quindi con cui il modello viene "addestrato". Nell'apprendimento supervisionato il modello costruisce le regole per dividere i dati in categorie, e i casi di apprendimento sono categorizzati a priori; nell'apprendimento non supervisionato il modello genera autonomamente le categorie e nell'apprendimento per rinforzo il sistema elabora informazioni con lo scopo di raggiungere un obiettivo, e la supervisione si limita ad indicare se l'obiettivo sia stato raggiunto.
In generale nelle applicazioni per la meteorologia possiamo, a seconda dei casi, applicare tutti i paradigmi di apprendimento macchina. Vediamo qualche idea di applicazione.
Un primo esempio sono i riconoscitori grafici che nella meteorologia osservativa giocano un ruolo crescente nel fornire informazioni che sarebbero difficilmente ottenibili con la strumentazione ordinaria, come il riconoscimento della superficie innevata o alluvionata da immagini di webcam o satellite.
Affine a questo, si può immaginare di implementare un identificatore di strutture temporalesche in tempo reale, un sistema che partendo da immagini radar e satellitari, assieme a dati di origine modellistica che indichino la natura del flusso in quota ed indici di instabilità termica, fornisca una classificazione della pericolosità. In questo caso la sorgente di apprendimento potrebbe essere una serie di modelli concettuali delle strutture convettive, oppure una serie di casi storici collegati ad effetti al suolo, producendo quindi un apprendimento supervisionato.
Come ulteriore esempio, presso il Centro Meteorologico di Teolo di ARPAV, è stato fatto un esperimento di questo tipo, tra il 2010 e il 2012. Nella fattispecie era stato impostato un sistema ad albero decisionale dinamico, che attribuiva ad ogni cella di una rappresentazione raster della pianura veneta un valore di probabilità di presenza di nebbia. L'albero decisionale lavorava su variabili osservative (temperatura, umidità, pressione, differenziale di pressione, valore di una combinazione di canali satellitari, stima della natura dello strato limite) ed era istruito in modo supervisionato dalla casistica di visibilità per classi registrata nell'intervallo di vita dei 10 visibilimetri distribuiti sul territorio. Giorno per giorno il sistema arricchiva la propria cultura sulla correlazione tra le variabili osservative e la visibilità, permettendo una estrapolazione basata non solo su semplici ipotesi geometriche, ma anche sulle grandezze fisiche derivanti da osservazioni dirette e indirette.
Una categoria di intelligenza artificiale diversa, in meteorologia, potrebbe essere questa: un sistema capace di fornire un'informazione "descrittiva" del tempo previsto mirata ad utenti umani. Possiamo ipotizzare che questa macchina, a partire dai modelli numerici di previsione, applichi degli schemi parametrizzati per la selezione dei contenuti, l'aggregazione geografica e temporale; il sistema prenderebbe le informazioni numeriche da uno o più modelli meteorologici, elaborandole e infine traducendole in linguaggio umano. L'apprendimento può essere generato dal feedback dell'utente per esempio alla domanda del sistema "è stata utile questa previsione?" per calibrare la significatività del livello di aggregazione, oppure "è chiara la previsione?" per calibrare alcune formule del linguaggio utilizzato. In questo caso i parametri soggetti a calibrazione possono essere i livelli di aggregazione geografici e temporali, e dei punteggi da associare ad un dizionario specifico.
Sono solo esempi, di una disciplina che ha sicuramente un futuro ricco di potenzialità, di cui alcune sono già esplorate e in parte sfruttate; a questo proposito infatti va ricordato che i centri di ricerca che producono modellistica numerica fanno già uso di metodi di clustering, per esempio per accorpare le varianti di scenario dei sistemi ensemble, come anche nelle applicazioni di confine tra meteorologia e climatologia viene impiegato il clustering per ricostruire pattern meteoclimatici principali.
Le variabili che possono essere considerate sono moltissime, come anche è molto vario il panorama dei metodi di apprendimento applicabili al machine learning per la previsione meteorologica.
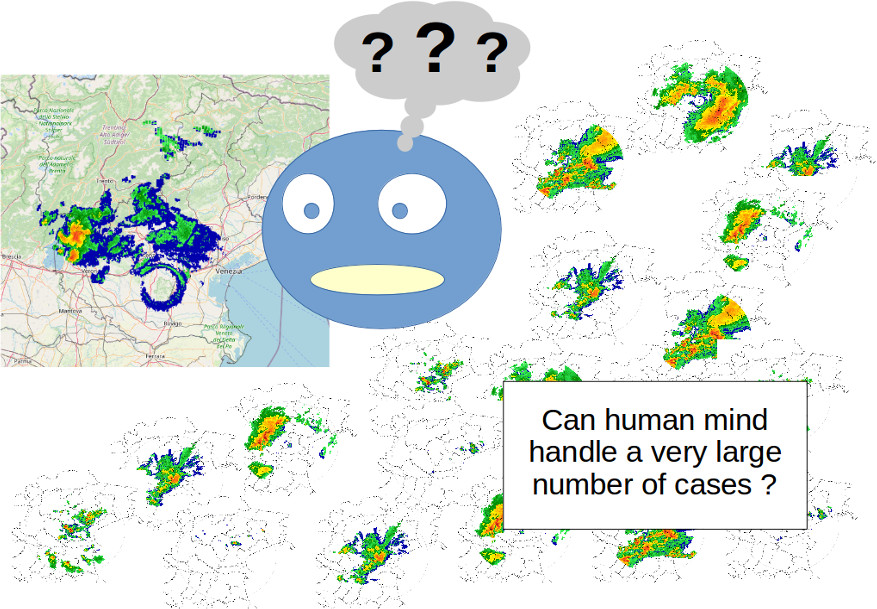
L'intelligenza umana è alla base dell'analisi esperta in meteorologia. Ma possiamo realmente ricordare e fare riferimento a tanti casi quanti vorremmo? Fonte ARPAV
Che prospettive migliorative offrono i metodi di IA nella meteorologia?
L'IA offre la possibilità di trattare una quantità di dati ed esempi che la mente umana non ha il tempo materiale di considerare. Ricordare l'enormità delle casistiche passate, correlare le diverse previsioni modellistiche (e i relativi errori) alla realtà riscontrata, applicare le varianti dei modelli concettuali all'osservazione diretta sono tutte sfide alla capacità di analisi, di sintesi, e banalmente alla capacità mnemonica del previsore e in generale del cervello umano.
L'intelligenza artificiale può anche aggiungere una visione analitica più lucida, non limitata da elementi convenzionali o da prassi abituale, nella scelta di uno scenario previsionale; in questo senso l'IA potrebbe risultare perfino più creativa rispetto all'approccio umano.
Questo aspetto, potenzialmente entusiasmante, vede comunque il contraltare nel limite dell'apprendimento, in quanto un sistema, pure se in continuo apprendimento, a fronte di una situazione completamente nuova può mancare degli strumenti per valutare le conseguenze.
Da un altro lato, l'integrazione dei sistemi osservativi con metodi intelligenti potrà dare spazio a nuove informazioni che possono tra l'altro contribuire al perfezionamento dello scenario di analisi da cui inizia il lavoro della modellistica meteorologica.
Certamente anche l'aspetto comunicativo può essere arricchito dall'impiego di intelligenza artificiale mirata alla diffusione di previsioni, anche eventualmente dedicate ad impieghi e necessità specifiche dell'utente.
Per concludere con un'osservazione un po' teorica, l'intelligenza naturale o artificiale che sia, dovrebbe esprimere quel di più che supera il semplice processo di analisi, e che permette di produrre sintesi. Per capirci con un esempio, passando dall'elenco di valori di pressione in un'area geografica alla frase "questo è un ciclone" abbiamo operato una sintesi. L'atmosfera è un sistema non lineare, il cui comportamento ci risulta impossibile da riprodurre nella sua interezza e nei dettagli, se non per brevi periodi e con errori nella simulazione che evolvono nel tempo in maniera caotica. L'intelligenza ci permette di identificare strutture e comportamenti quasi lineari in ambienti non lineari, come stimare la traiettoria di un temporale, notare elementi di ciclicità nell'evoluzione delle strutture cicloniche e anticicloniche; questo assomiglia al processo intelligente con cui per esempio identifichiamo riccioli quasi regolari in aree dell'insieme di Mandelbrot, o tratti rettilinei negli attrattori di Lorenz.
Questa potenzialità mi sembra, a valle del colossale lavoro di simulazione fisica fatta dai modelli meteorologici, l'aspetto più promettente per l'applicazione dell'intelligenza artificiale nella meteorologia.


