





Un database mondiale per studiare le disuguaglianze

Un database sulle disuguaglianze e sui servizi delle città. Si chiama DUIA (Database on Urban Inequality and Amenities) e include dati sullo sviluppo socio-economico di 86 diverse città del mondo. L’obiettivo è quello di cercare di fornire un’analisi comparativa in quei campi che solitamente sono privi o quasi di dati. Il DIUA per ora cerca di affrontare le questioni non risolte da altri database sulle città, aggregando dati dei confini delle città attraverso l’Atlas of Urban Expansion, l’IPUMS (Integrated Public Use Microdata Series) e lo fa utilizzando software open source e condividendo gli script (rilasciando uno script R) per garantire trasparenza e replicabilità. Le informazioni che il DUIA prende in considerazione vanno dalle caratteristiche dell'abitazione e della famiglia, al livello di istruzione, dalla proprietà di beni ed elettrodomestici all’accesso ai servizi, con l’obiettivo di rappresentare un passo avanti nello studio sistematico della disuguaglianza e dei servizi nel tempo e tra le città.
“ Il DUIA (Database on urban Inequality and Amenities) include dati sullo sviluppo socio-economico di 86 diverse città del mondo
La premessa con cui è stato realizzato questo progetto è quella della mancanza di un'infrastruttura di dati completa e autorevole per analizzare le città. La difficoltà nel costruire database con un'ampia copertura internazionale, secondo il ricercatore Frederico Roman Ramos, che ha introdotto DIUA su Plos One, è data dal fatto che “la quantità di dati disponibili e le modalità di misurazione differiscono notevolmente tra i paesi. Di conseguenza, i database in genere includono solo un numero limitato di città del Nord del mondo o un numero limitato di variabili”.
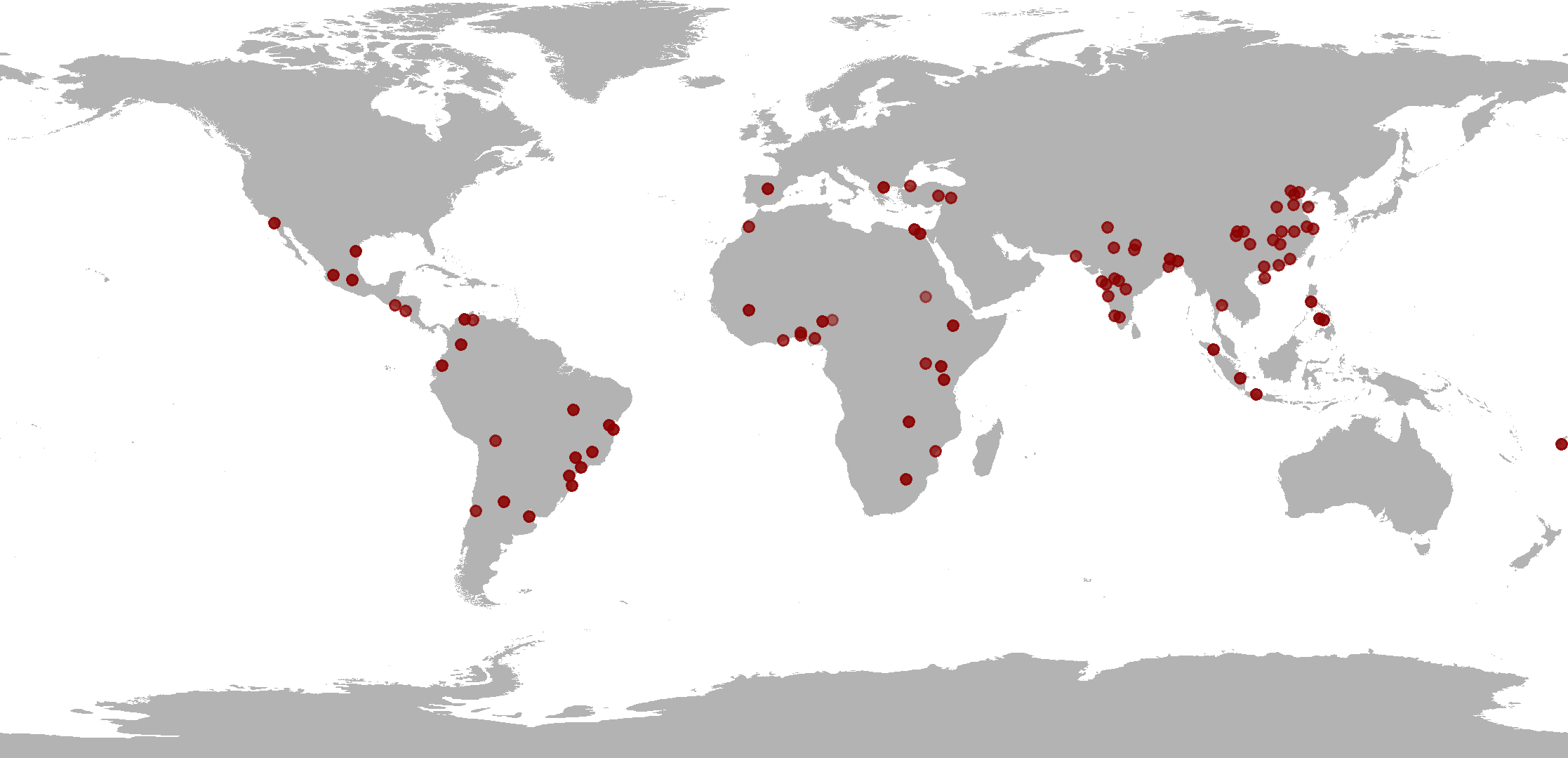
Con il DUIA si cerca di andare oltre prendendo come campione le stesse città analizzate da UN-Habitat. I dati per queste 86 città sono presi, come abbiamo già detto, dall’Atlas of Urban Expansion, e dall’IPUMS (Integrated Public Use Microdata Series).
L’IPUMS in particolare fornisce informazioni a livello individuale e familiare, e significa, ad esempio, che non solo si può sapere quale percentuale della popolazione di una città ha accesso all'acqua, ma anche quali gruppi non hanno o hanno accesso. Oltre a ciò, l’IPUMS fornisce anche i dati GIS, cioè quelli utili a stabilire il confine della città. Per alcuni paesi, tra cui Cina e India, riporta la presentazione del database, “la disponibilità di variabili di microdati è ancora limitata nell'IPUMS”, in che significa che non è possibile effettuare l’analisi a livello individuale o familiare. In questo caso il DUIA prende in considerazione i dati provenienti direttamente dalle rispettive agenzie statistiche nazionali.
Complessivamente quindi il DUIA include i dati di 86 città diverse, 56 di queste ottenute da IPUMS (tutte tranne le cinesi ed indiane).
Il metodo per assemblare tutti questi dati nel database DUIA prevede poi tre passaggi principali: selezione ed estrazione dei dati; compilazione e integrazione dei dati; e aggregazione di statistiche a livello di città. Tutti i dati, il codice e il software sono disponibili gratuitamente ed ogni passaggio può essere replicato utilizzando gli script R accessibili sul GitHub del progetto.
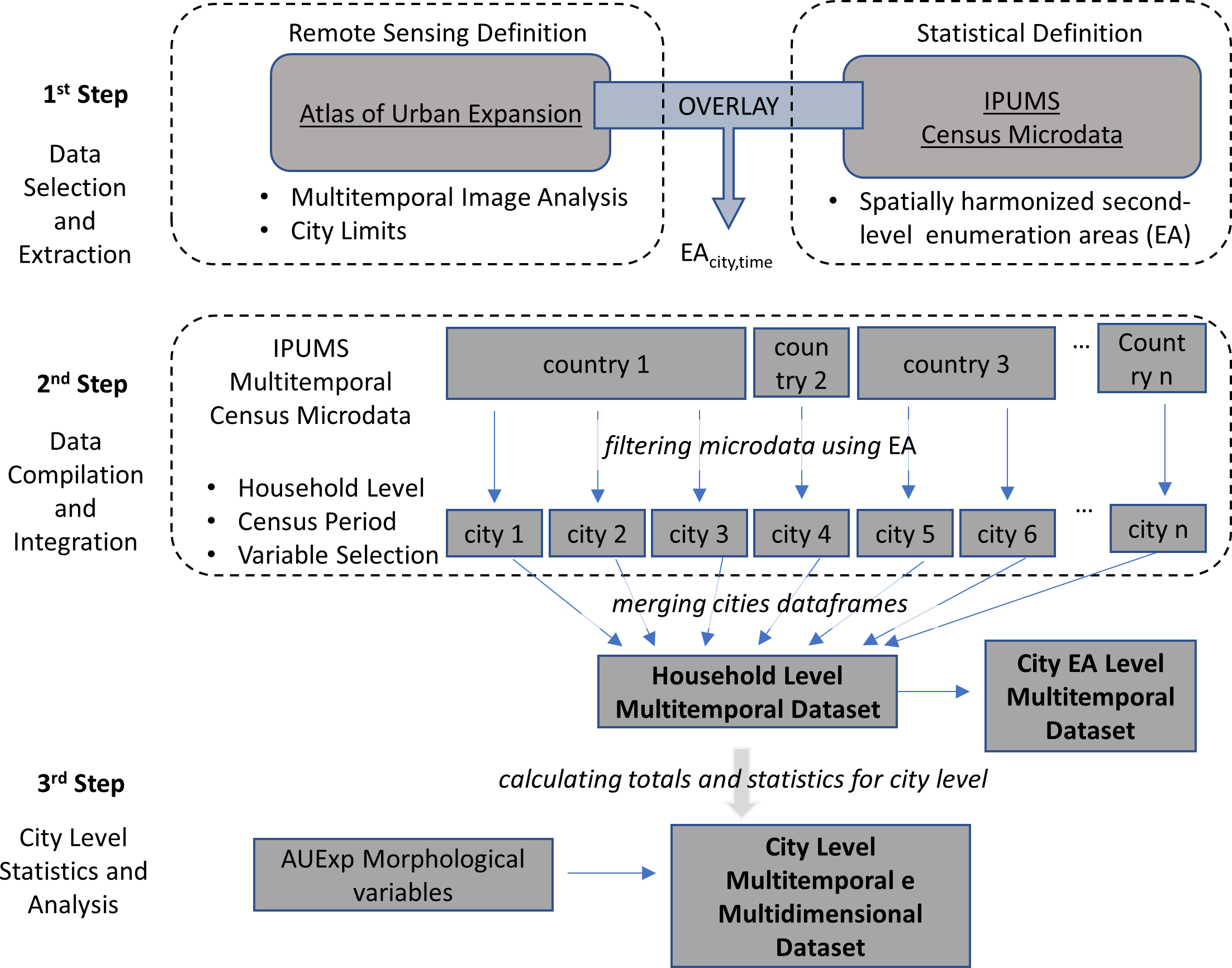
I codici R che si trovano nel repository di GitHub sono organizzati in tre cartelle diverse, che seguono le diverse fasi descritte nel flusso di lavoro di DUIA. La prima contiene una serie di codici specifici del paese, e consente la selezione dei campioni IPUMS in base all'operazione di sovrapposizione geografica. Per fare questo vengono utilizzati degli shapefile geografici specifici, basati naturalmente sull’ultimo anno disponibile su IPUMS e sui database GIS.
Sempre nella stessa cartella, come anche nelle altre due, c’è un file di spiegazione che, in questo caso, descrive come sono stati estratti i campioni nazionali da IPUMS, questo al fine di rendere possibile una replica.
La seconda cartella contiene il codice utilizzato nel processo di integrazione. Questo descrive le operazioni utilizzate per rendere compatibili i dati specifici del paese, inclusa la standardizzazione delle variabili e la formattazione. La terza cartella infine contiene il codice utilizzato per generare il database aggregato a livello di città.
Gli sviluppatori hanno quindi reso accessibile lo script diviso in tre passaggi, all’interno dei quali c’è una spiegazione su come usare il tutto. L’aspetto principale che si trova su Github è la quantità di microdati disponibili a livello di famiglia, composto da circa 50 milioni di campioni di famiglie. Il database a livello di città poi consente un accesso semplice e diretto a 33 variabili in diverse categorie come "accesso all'acqua corrente", "accesso a Internet" e "livello di istruzione".
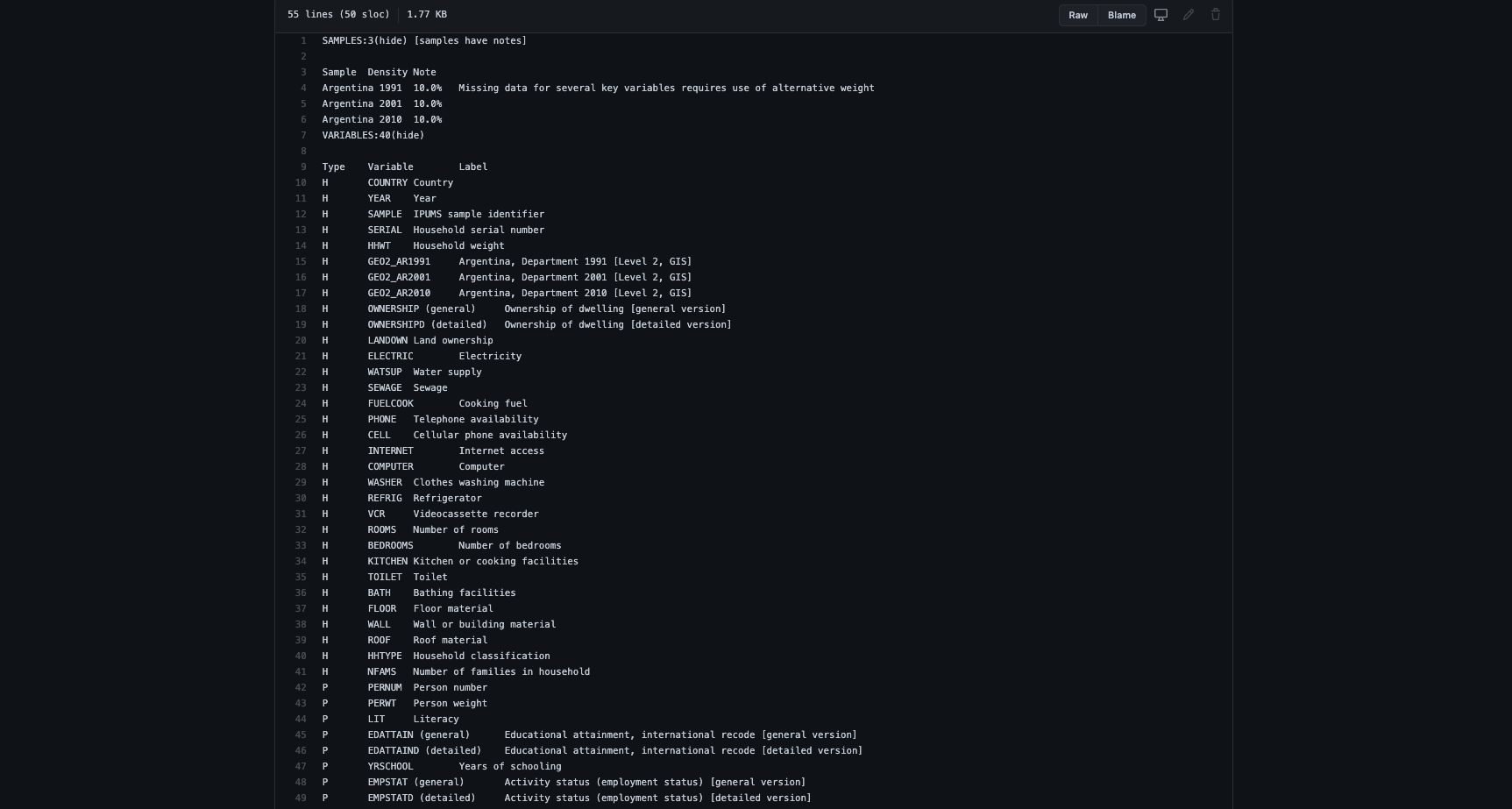
Esempio dati estratti da IPUMS per quanto riguarda l’Argentina
Fino ad ora abbiamo spiegato il funzionamento del database DUIA, ma vediamo quali sono i risultati. Un’opportunità del DUIA è proprio quella di poter studiare le disuguaglianze all'interno e tra le città. Facendo un esempio concreto di come funziona questo database con relativi script, vediamo come sia stata analizzata l’evoluzione della disuguaglianza di 36 diverse città rispetto anche al loro Paese.
La maggior parte delle città analizzate, 30 su 36, mostrano una diminuzione della disuguaglianza nel tempo ed un sostanziale collegamento con il contesto nazionale. In un solo caso, Valledupar, città nel nord della Colombia, la disuguaglianza è aumentata nonostante la diminuzione complessiva osservata nel Paese.
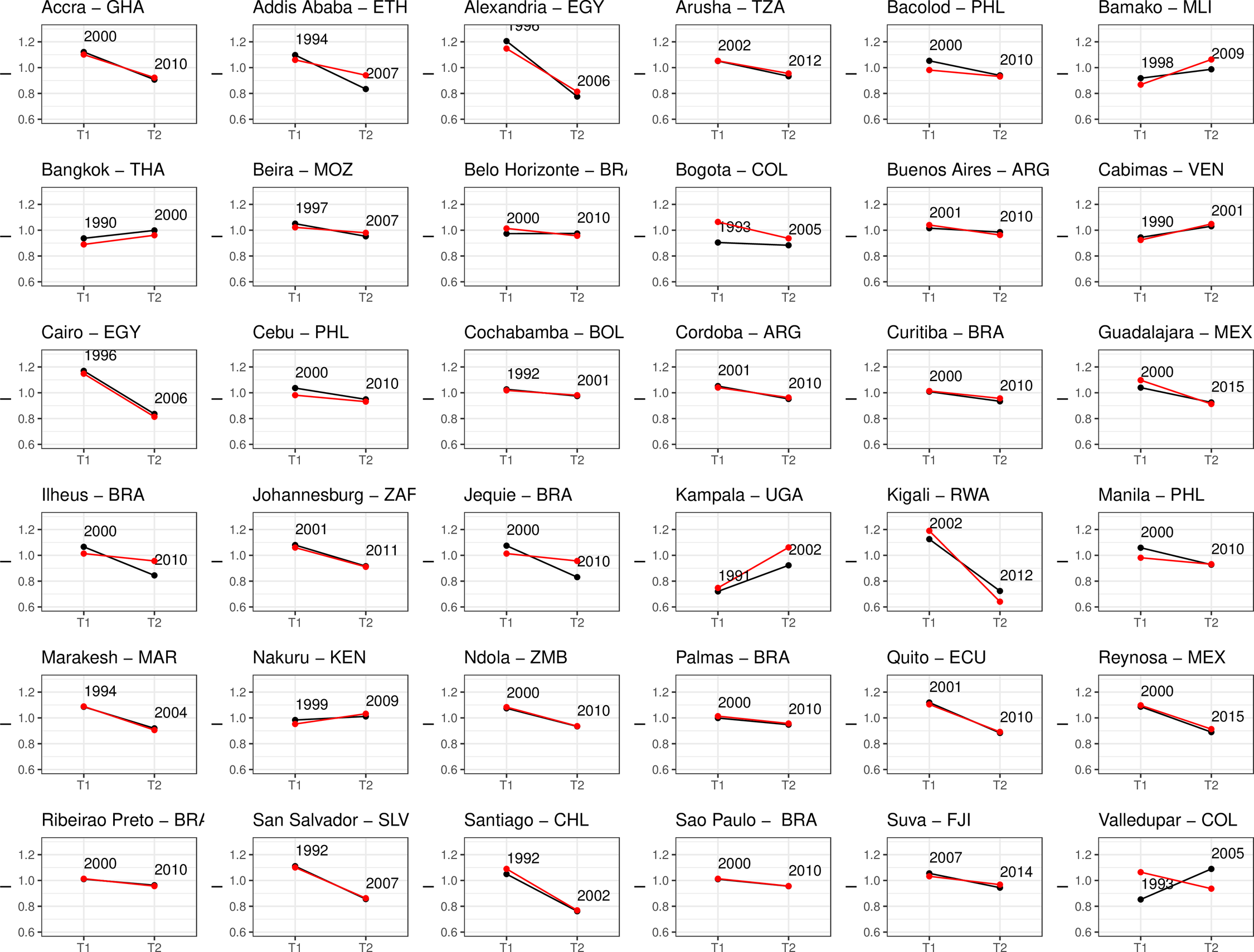
Prendendo invece in considerazione un indicatore preciso, come ad esempio l’accesso all’acqua corrente, vediamo come il database possa venire in soccorso per analizzare come ciò si sia sviluppato nel tempo. Nella presentazione del DUIA si illustra un'analisi comparativa in cui si esplora se la famiglia avesse o meno l'acqua corrente. Per farlo i ricercatori hanno preso i dati dell’accesso all’acqua corrente per 31 città dall’IPUMS mentre per 13 città indiane e 21 cinesi la fonte è stata direttamente la rispettiva agenzia statistica.
La raccolta di grafici per le 86 città è stata presentata in un’immagine decisamente esplicativa. Vi è infatti una tendenza generale nella direzione di un aumento dell'accesso ed in media, le città del campione hanno avuto una copertura del 74% dell’accesso all’acqua corrente.

L’obiettivo del DUIA è chiaro e lodevole, ma per completezza d’informazione bisogna notare che lo stesso database presenta diverse limitazioni. Alcune sono state esplicitate direttamente dagli autori su Plos One, che ritengono come ci siano delle problematiche per quanto riguarda innanzitutto la reperibilità di dati affidabili e comparabili tra loro. Questi dati infatti derivano in molti casi dai censimenti e la loro affidabilità è strettamente collegata a come sono stati raccolti, consapevoli anche che i censimenti stessi sono realizzati in momenti diversi tra diverse città.
Il campione di città inserite nel DUIA poi non è rappresentativo e “può essere utilizzato al massimo per approssimare le tendenze generali”.Infine, una terza limitazione messa in evidenza dagli autori, è che DUIA richiede una notevole potenza di calcolo. Non si può poi realizzare un’analisi incentrata sui quartieri della città, o quantomeno non lo si può fare per tutte le città prese in considerazione. Il progetto insomma è sicuramente interessante, ma alcune difficoltà sembrano troppo elevate da superare per farlo diventare uno standard per le analisi comparative mondiali.

