





Possiamo usare i dati del web per combattere la pandemia?

Negli scorsi giorni ci sono stati diversi appelli da parte di esperti e associazioni per migliorare la qualità e la quantità di dati che vengono raccolti e analizzati nel monitoraggio dell’epidemia da CoVid-19. È stato chiesto di rendere i dati pubblicamente accessibili, in modo che più mani esperte possano maneggiarli. Tra questi appelli c’è stato anche quello in favore di un utilizzo dei dati raccolti dai colossi del web, come Google e Facebook, per avere informazioni più precise, più granulari, sulla mobilità della popolazione e individuare o magari addirittura prevenire la formazione di focolai.
Di come i dati del web potrebbero venire in nostro aiuto nella gestione della pandemia abbiamo parlato con Walter Quattrociocchi, fino a qualche mese fa direttore del Data and Complexity Lab dell’università Ca’ Foscari di Venezia, ma da qualche settimana traslocato alla Sapienza di Roma dove è professore associato del dipartimento di informatica e direttore del Center of Data Science and Complexity for Society. Walter Quattrociocchi è anche membro della task force governativa sui web data per l’emergenza coronavirus. Quest’estate il suo gruppo ha pubblicato un lavoro su Pnas che utilizza proprio i dati di mobilità messi a disposizione dal programma “Data for good” di Facebook, azienda con cui il nuovo laboratorio di Quattrociocchi ha recentemente iniziato una collaborazione di ricerca in chiave anti-pandemica.
Innanzitutto per poter utilizzare la mole di dati che verrebbero presi dal web serve un’infrastruttura di raccolta dati, “e quale debba essere questa infrastruttura al momento non è chiaro a nessuno” commenta Walter Quattrociocchi. “L’unico tentativo di far funzionare un’applicazione di contact tracing non è andata benissimo”. Ci sono diversi ordini di motivi per cui l’app Immuni non ha funzionato come si sperava: tecnici, gestionali e di comunicazione. “Non è stata presa in considerazione tutta la complessità che implementa quel processo. Ma questo fa anche parte di ogni tentativo di provare a fare qualcosa di nuovo”.
Walter Quattrociocchi, membro della task force governativa sui web data, discute di come usare i dati di Facebook per gestire la pandemia. Montaggio di Barbara Paknazar
Dati di Facebook
Per quanto riguarda la possibilità di utilizzare i dati detenuti da Facebook Quattrociocchi sottolinea che le cose potrebbero essere più complicate di come ce le si immagina. “Il punto è che la granularità dei dati che viene fornita da Facebook non è così precisa, altrimenti non avremmo avuto bisogno di Immuni”, che utilizza il bluetooth per registrare la vicinanza degli smartphone a distanza di pochi metri. “I dati che prende Facebook a livello di distanza sono distribuiti in celle da 500 metri per 500 metri”. In altri termini la granularità è molto larga e non permetterebbe di fare analisi sui contatti, ma solo eventualmente sulla densità dell’area. Inoltre Facebook fa la rilevazione della georeferenziazione ogni 8 ore, riporta Quattrociocchi, il che è diverso da avere informazioni precise sugli spostamenti.
Chi propone l’utilizzo di questa tipologia di dati, secondo Quattrociocchi, lo fa un po’ troppo frettolosamente, senza avere grande familiarità con i dettagli tecnici del problema. “La questione è di difficile risoluzione sia da un punto di vista tecnico sia normativo. Si fa presto a dire espropriazione proletaria dei dati di Facebook, ma come si fa se non hai nemmeno l’infrastruttura per prenderli e per gestirli. Né si ha lo strumento legislativo per farlo, perché Facebook fa riferimento alla struttura legislativa che hanno a Menlo Park negli Stati Uniti, non a quelle nazionali europee”.
“ Sarà necessaria una collaborazione tra chi i dati li ha e chi le politiche le farà. È una questione che va gestita e normata senza discorsi ideologici e pregiudizi Walter Quattrociocchi
Tuttavia con i dati della mobilità del programma “Data for good” qualcosa lo si può fare e il gruppo coordinato da Quattrociocchi ha pubblicato a luglio su Pnas un lavoro in cui viene stimato l’effetto del lockdown sulla situazione socioeconomica dei comuni italiani (non venivano quindi indagati aspetti sanitari o epidemiologici). “Data for good è un programma che Facebook ha lanciato quando è partita la pandemia per cercare di facilitare il lavoro dei ricercatori e delle istituzioni nel contenerla. Io in quanto ricercatore nel campo della data science e membro della task force ho avuto un processo di interlocuzione abbastanza facile per l’accesso a questi dati. Anche altri hanno avuto accesso a questi dati, ma dipende come li utilizzi. Questa è una preoccupazione non soltanto di Facebook ma anche della politica. Adesso va tanto di moda dire ‘l’ho trovato nei dati’, ma così vengono dette anche tante inesattezze. Ad esempio è stato detto che in base a cosa uno scrive sui post Facebook – sto bene, sto male, sono asintomatico – si riesce a capire come si diffonde la pandemia. Peccato che in Italia vengono fatti dai 3 ai 5 milioni di post al minuto. Scremare questa quantità è computazionalmente impossibile e poi la significatività statistica di questi post è pari a zero, verrebbe percepita come rumore da qualsiasi tipo di algoritmo di analisi dati”.
“ Il business model di queste aziende è fondato sui dati, devono trovare delle strategie e delle modalità di interazione che permettano loro di preservare quell’interesse Walter Quattrociocchi
Dati di Google Maps
Tuttavia, nonostante la complessità, da buoni dati di mobilità è possibile ottenere informazioni epidemiologiche utili. Lo dimostra uno studio pubblicato su Nature il 10 novembre che ha utilizzato i dati di geolocalizzazione, con cadenza oraria, dei telefoni cellulari di 98 milioni di persone negli Stati Uniti, per un totale di 5,4 miliardi di rilevazioni, per un periodo che va dai primi di marzo ai primi di maggio. I dati sono stati ottenuti in forma anonimizzata da SafeGraph, un’azienda che li raccoglie a scopo commerciale (ad esempio per stabilire quali sono le attività commerciali più frequentate) e sono stati confrontati con quelli di Google Maps. I ricercatori hanno poi individuato circa 57.000 aree urbane di interesse e più di 550.000 punti di interesse (luoghi di aggregazione come ristoranti o chiese). È stata così riprodotta una rete di spostamenti alla quale è stato applicato un modello epidemiologico SEIR, che tiene conto del numero dei suscettibili, degli esposti, degli infettati e dei rimossi (guariti). Il modello è stato calibrato con i dati dei contagi registrati dal database del New York Times per ciascuna area metropolitana. Nella figura riportata sotto si vede che, per quanto riguarda l'area di Chicago, il modello è stato calibrato solo con i dati aggiornati fino al 15 aprile. Ciononostante, e nonostante la mobilità sia stata fortemente modificata dalle misure restrittive, la curva del modello (in blu) segue la stessa traiettoria della curva dei contagi reali (in arancione), mostrando che il modello basato sulla rete di mobilità è capace di predire accuratamente l'andamento dei contagi.
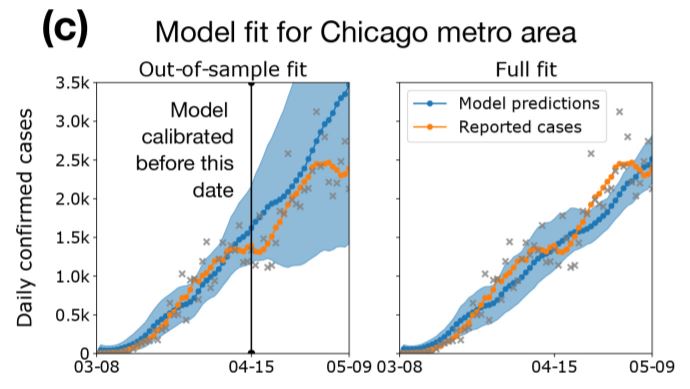
In blu la predizione del modello, in arancione il reale andamento dei contagi nell'area metropolitana di Chicago. Tra le due curve c'è corrispondenza ("fit"). Chang et al. 2020, Nature.
Inoltre è stato possibile vedere che pochi luoghi di aggregazione (il 10% dei punti di interesse) sono responsabili della maggior parte dei contagi (85%), in accordo con le conoscenze che già avevamo sull’importanza degli eventi di superdiffusione.
“Lo studio è fatto molto bene: mappano i punti ti interesse sull’andamento del contagio e hanno corrispondenza” commenta Walter Quattrociocchi.
Secondo l’immunologa Antonella Viola, che ha commentato lo studio di Nature sulla sua pagina Facebook, si possono ricavare informazioni di notevole interesse per le politiche sanitarie: “la riduzione della massima occupazione nei punti di interesse, ovvero lo stabilire che solo un certo numero di persone può trovarsi per esempio in un negozio ad ogni momento, è estremamente efficace per abbattere i contagi. Questo permette di lasciare le attività operative senza troppe penalizzazioni”. Tuttavia, commenta Antonella Viola, “c’è una grande variabilità fra esercizi della stessa categoria in luoghi differenti, e non è facile quindi generalizzare, anche se, in media, nel modello la riapertura (è proprio analizzando le riaperture che si capisce meglio quali sono i punti più a rischio) attribuisce la maggior pericolosità a ristoranti con servizio al tavolo, palestre, hotel, caffè e luoghi di culto”.
Lo studio pubblicato su Nature è un primo passo verso un lavoro di tracciamento che i dati delle grandi aziende del web potrebbero contribuire a rendere più efficace, ma la strada è lunga, i problemi irrisolti ancora molti e non è detto si riuscirà a ottenere risultati utili alla prevenzione epidemica in tempi brevi.
Rapporto tra dati e società
Secondo Quattrociocchi viviamo un momento storico in cui ci si rende conto che il rapporto tra società e dati è arrivato a un punto nodale e il loro sfruttamento, nel rispetto della privacy, può portare enormi benefici alla società. Ma trovare il trait d’union non è affatto banale. “Io come scienziato la privacy la vivo come un ostacolo, nel senso che limita il tipo di studi che posso fare. Da cittadino però la sento come una garanzia, e trovare il compromesso tra queste posizioni è difficile. Nel Gdpr (il regolamento sulla privacy vigente in Europa, ndr) tuttavia è prevista una deroga alla privacy per questione di crisi particolarmente gravi”.
Ma se un ordine di problemi è rappresentato dalla privacy, un altro forse ancora più ingombrante è rappresentato alla proprietà dei dati: Facebook e Google sono realtà private che mirano ad accumulare profitto e il loro modello di guadagno è basato sulla raccolta dei dati degli utenti. “Naturalmente il business model di queste aziende è fondato sui dati, devono trovare delle strategie e delle modalità di interazione che permettano loro di preservare quell’interesse, ma al contempo vogliono risolvere la loro posizione rispetto al sociale. Data for good è una di queste modalità”.
Quattrociocchi crede che rendere via via più accessibili e utilizzabili questi dati sia nei programmi di Facebook, “anche se io sono solo un interlocutore. Ma credo che ci sia l’intenzione di costruire un rapporto virtuoso in questo senso. A noi hanno fornito dati completamente anonimizzati, aggregati, perfettamente in linea con i nostri regolamenti sulla privacy”. Però, ribadisce Quattrociocchi, quei dati non permettono di capire l’andamento della pandemia al livello di granularità desiderato. “Per quello ci voleva un’app come Immuni, che purtroppo è stata un’occasione persa”.
“ Credo che sia difficile che lascino libero e totale accesso ai loro dati. Comunque sia loro si pongono come intermediari, e rilasciano solo quello che loro ritengono sia utile Walter Quattrociocchi
Tuttavia Quattrociocchi ritiene anche che la disponibilità dei colossi del web nei confronti di un utilizzo aperto dei loro dati non sarà mai totale. “Credo che sia difficile che lascino libero e totale accesso ai loro dati. Comunque sia loro si pongono come intermediari, e rilasciano solo quello che loro ritengono sia utile. Sul lungo termine non ho idea di cosa accadrà, siamo sicuramente nel mezzo di un passaggio epocale, per cui la data-driven policy sarà la politica chiave per i prossimi 30-40 anni. Perciò bisogna creare le condizioni per cui queste politiche che regoleranno l’utilizzo dei dati possano essere implementate, realizzate. Pertanto sarà necessaria una collaborazione tra chi i dati li ha e chi le politiche le farà. È una questione che va gestita e normata senza discorsi ideologici e pregiudizi”.
Secondo Quattrociocchi sono tre i fondamentali nodi che andranno sciolti. Il primo punto riguarda restringere il cerchio della discussione attorno a chi è competente “e far sparire tutti quelli che chiacchierano sui dati senza aver capito quali sono i termini del problema, perché altrimenti dovremmo spendere buona parte delle nostre energie nel riportare il discorso nell’alveo di una prospettiva scientifica accettabile”.
In secondo luogo per Quattrociocchi va instaurato un rapporto virtuoso tra accademia, politica e chi detiene i dati: “bisogna trovare delle modalità di interazione che evitino frizioni (il dipartimento di giustizia statunitense ha fatto causa a Google accusandola di aver gestito il monopolio dei dati in modo contrario all'antitrust, ndr) perché altrimenti la reazione è di totale chiusura. Il caso Cambridge Analytica a riguardo è stato esemplare. Per quanto molti brindino alla vittoria del fatto che la nostra privacy sia stata salvata, di converso ha avuto l’effetto di diminuire la quantità di dati che Facebook mette a disposizione. Dopo CA, ha limitato tantissimo l’accesso alle API” ovvero le application programming interface, che sarebbero le procedure di linguaggio di programmazione necessarie a svolgere un determinato compito, come scaricare i dati delle interazioni sul social network. “Le Api prima erano pubblicamente accessibili da tutti, ora sono state limitate enormemente”.
Il terzo punto, non meno importante secondo Quattrociocchi, riguarda la comunicazione della scienza dei dati, promuovere un’alfabetizzazione ai dati, descrivere limiti e vantaggi di questo nuovo mondo che si sta affacciando. “Un ambito di cui si sta iniziando a parlare molto in questi giorni è la cosiddetta network medicine, che si regge su dati molto sensibili, ma che apre un mondo di possibilità in termini di diagnosi e cure. Non risolverà tutti i problemi ma ci permetterebbe di capire cose davvero importanti. È un passo che sta lì in attesa di essere compiuto: il problema della privacy è reale, ma quanto pesa quella privacy rispetto al vantaggio che potrebbe essere ottenuto? Possibile che non riusciamo a trovare il punto di incontro, ovvero una formulazione di quel dato che sia a norma di privacy e che permetta di essere usato per fare un avanzamento scientifico di cui gioverebbe l’intera società? Sono tutti punti cardine di cui bisognerebbe parlare, ma con chi ne capisce qualcosa”.


